
This morning (Jun 21, 2022 – 06:43 UTC) Cloudflare reported a “wide-spread” outage that was affecting a large number of very popular services. Impacted sites included Discord, Shopify, Fitbit, NordVPN and ourselves. This blog post aims to explain what the issue was and how it affected us.
From Cloudflare:
“A critical P0 incident was declared at approximately 06:34AM UTC. Connectivity in Cloudflare’s network has been disrupted in broad regions.
Customers attempting to reach Cloudflare sites in impacted regions will observe 500 errors. The incident impacts all data plane services in our network.”
What is Cloudflare?
According to their website; “Cloudflare is one of the biggest networks operating on the Internet. People use Cloudflare services for the purposes of increasing the security and performance of their websites and services.”
They’re a CDN (Content Delivery Network) for caching its customers’ content around the globe. This enables its customers to speed up the delivery of their services to their users. Additionally, Cloudflare provides other related services such as DNS and SSL hosting, along with performance enhancement and security protection tools.
Cloudflare is used by many of the world’s largest brands and is trusted with delivering its customer’s content globally. This means that many services we take for granted rely on Cloudflare for their service delivery. However, this also means there is a single point of failure.
What happened?
As quoted at the start of this post; Cloudflare appeared to have had a major incident that affected end-users trying to reach services that use Cloudflare.
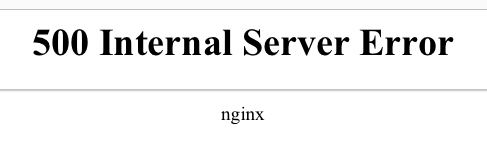
The result was end-users being met with a “500 error”. This is an HTTP code that means an internal server error has occurred. This error prevented the desired website from loading. Cloudflare has yet to release more information about what caused the problem, but it resulted in widespread disruption.
UPDATE: Cloudflare has released this statement about the incident.
How did this affect RapidSpike?
The good news is that our backend systems, APIs and monitoring software do not rely on Cloudflare proxying for their services to be operational. We use Cloudflare for our DNS in these systems, but as this was not affected by the outage we were able to continue monitoring and alerting.
However, our website, web app and public status pages all use Cloudflare for traffic proxying to provide SSL hosting and other Cloudflare features to help with performance and security. For this reason, if you tried to view any of those front-end services you will have been met with a 500 error similar to that in the earlier image.
As we were able to continue monitoring, some of our customer’s returned to a worrying site on their monitoring wallboards:
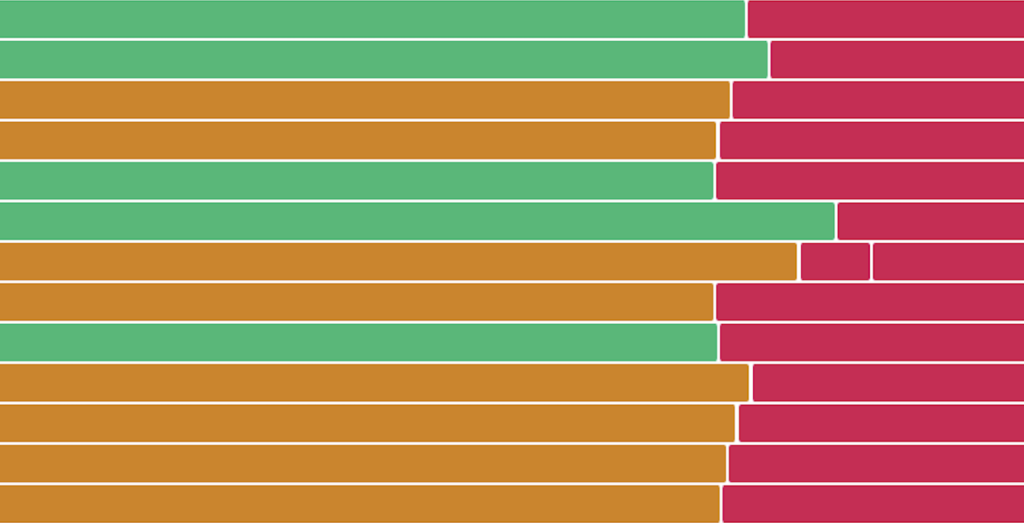
By 07:20 UTC Cloudflare had implemented a fix and was “monitoring the results”. Our front-end services came back online very quickly after this had happened. By 08:06 UTC Cloudflare declared the incident fully resolved.
Future Avoidance
Unfortunately, too much of the delivery of our front-end services rely on Cloudflare’s proxying services to work correctly. However, we will be investigating whether there is an option that we could have switched to temporarily in order to provide better error messages to explain the issue to our users.





